

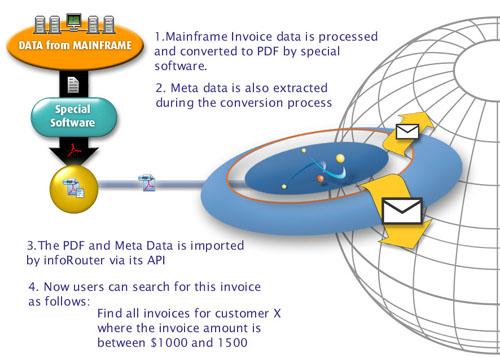
In this case study, we explore how infoRouter’s Document Management Software can efficiently capture and manage data from mainframe systems. A third-party tool, Formscape, is used to extract data from mainframe spool files, converting them into PDF documents and integrating them with infoRouter for easy access and management.
By using this process, organizations can quickly and securely upload critical documents like invoices to infoRouter, making them instantly accessible to authorized users. The setup allows for seamless data exchange between legacy mainframe systems and modern document management workflows.
How the Process Works
- Mainframe spool files are converted to text using Formscape.
- These text files are then transformed into individual PDF invoices.
- Metadata is extracted from the converted text, containing key information like Invoice Number, Invoice Date, Invoice Amount, and Customer details.
- An XML file is generated to accompany the PDF, containing the extracted metadata.
- Both the PDF and its associated XML metadata file are stored in a dedicated folder monitored by infoRouter.
- Using the infoRouter API, the files are automatically imported into the system.
- The Smart Import feature in infoRouter places the invoice files into the appropriate document folders.
- During this process, infoRouter populates custom property fields of the invoice documents based on the information provided in the XML metadata file.
Outcome and Benefits
- The PDF invoices become fully searchable within infoRouter, allowing users to find documents using keywords and phrases from the content.
- The metadata extracted and populated into custom fields enhances search capabilities, enabling advanced queries based on specific document properties.
- Users can perform detailed searches, such as “All invoice files for customer XYZ with an amount greater than 1000,” quickly finding the documents they need.
The integration of mainframe data with infoRouter improves accessibility, searchability, and organization of critical business documents, providing a streamlined workflow that connects legacy systems with modern document management.
To explore more use cases, visit our Case Studies, Solutions, and Usage Scenarios page.